 Figure 1: Complex Networking Wiring inside a Datacenter [source].
Figure 1: Complex Networking Wiring inside a Datacenter [source].
PDF version is available at: [here]
Datacenter Networking (DCN) is one of the key components in datacenters1 The other two are computation and storage. and is crucial for the performance and stability of the applications deployed in the datacenters, such as Generative AI, serverless computing, etc. As a DCN researcher, I have been answering the question of How to build high-performance, intelligent and secure DCN for the past five years.
Figure 1: Complex Networking Wiring inside a Datacenter [source].
Answering this question is challenging due to the highly shared environment of the datacenter at that time, which results in irregular, unpredictable and distrustful networking communications.
Irregularity: The irregularities problem arises from different applications having diverse communication goals (e.g., throughput-sensitive or latency-sensitive) and patterns (e.g., peer-to-peer, incast), requiring different path selection and queue control strategies to achieve high performance.
To address this goal, I primarily employ the methodology of active sensing to enable the DCN to be aware of irregularities and take quick reactions to mitigate their performance degradation. Specifically, HERMES2 Hong Zhang, Junxue Zhang, Wei Bai, Kai Chen, and Mosharaf Chowdhury. Resilient Datacenter Load Balancing in the Wild. In Proc. of SIGCOMM 2017 is among the first to sense irregularities in congestion information on different paths and actively switch flows to their desired paths to achieve 10.0% better average flow completion time. ECN#3 Junxue Zhang, Wei Bai, and Kai Chen. Enabling ECN for Datacenter Networks with RTT Variations. In Proc. of CoNEXT 2019 senses queue buildups caused by irregularities in round-trip time (RTT) and actively marks ECN to eliminate the queue, thereby achieving 23.4% lower latency.
Unpredictability: Accurately predicting networking traffic patterns has long been a critical task in optimizing the DCN, especially for congestion control, flow scheduling, and more. Therefore, the DCN needs to be intelligent in handling the unpredictability of networking traffic.
To achieve this goal, I have developed machine learning-driven congestion control algorithms that precisely predict and control networking traffic. These algorithms have been deployed in real-world environments. MOCC4 Yiqing Ma, Han Tian, Xudong Liao, Junxue Zhang, Weiyan Wang, Kai Chen, and Xin Jin. Multi-objective Congestion Control. In Proc. of EuroSys 2022 leverages a multi-objective reinforcement learning (RL) algorithm to predict the optimal sending rate for different applications with diverse communication goals with 14.2× convergence time. Additionally, I have designed and opensourced LiteFlow5 Junxue Zhang, Chaoliang Zeng, Hong Zhang, Shuihai Hu, and Kai Chen. LiteFlow: Towards High-performance Adaptive Neural Networks for Kernel datapath. In Proc. of SIGCOMM 2022, which is the first userspace and kernel-space hybrid approach6 LiteFlow is mainly designed for the Linux OS, but the idea can be extended to other OSes. to efficiently deploy ML-based congestion control algorithms with 44.4% better throughput.
Distrust: In a shared environment, concerns about trust can arise due to the presence of potentially untrusted or malicious entities. These entities may attempt to eavesdrop on communications, compromise data integrity, or introduce security vulnerabilities. Therefore, a secure DCN, or even end-to-end data generation and consumption paradigm is needed.
To meet the requirements, I mainly incorporate a new encryption technology called homomorphic encryption7 Homomorphic encryption allows certain operations, such as addition and multiplication, to be directly performed on ciphertexts without decryption first. to enable an end-to-end data protection mechanism. To make this technology practical, I designed FLASH8 Junxue Zhang, Xiaodian Cheng, Wei Wang, Liu Yang, Jinbin Hu, and Kai Chen. FLASH: Towards a High-performance Hardware Acceleration Architecture for Cross-silo Federated Learning. In Proc. of NSDI 2023, a hardware-based accelerator that optimizes the computation bottleneck of homomorphic encryption by 2 − 3 orders of magnitude. Complementarily, GeniBatch9 Xinyang Huang, Junxue Zhang, Xiaodian Cheng, Hong Zhang, Yilun Jin, Shuihai Hu, Han Tian, and Kai Chen. Accelerating Privacy-Preserving Machine Learning With GeniBatch. In Proc. of EuroSys 2024, 2024 optimizes the networking and batching layer of privacy-preserving machine learning.
My research has garnered recognition from both the academic and industrial sectors. Notably, I have received the Best Paper Award at ICNP 202310 Best Paper: Enabling Load Balancing for Lossless Datacenters., as well as an Honorable Mention for the HKUST CSE Best PhD Dissertation Award, 2021-2211 CSE Best Dissertation Award 2021-22 Recipients Announced.. Furthermore, my research findings have been adopted by prominent enterprises such as China Construction Bank, WeBank, SenseTime, and others.
The advent of large language models (LLMs) has transformed datacenters. LLM training and serving are no longer occasional applications running on top of the network; they are becoming dominant workloads that shape the design of GPU clusters, memory systems, communication libraries, and datacenter networks. This shift motivates my current research question: How should we co-design datacenter networks and ML systems for LLM workloads?
 Figure 2: LLM Revolution [source].
Figure 2: LLM Revolution [source].
My past work studied DCNs as a general-purpose substrate for shared, irregular, and unpredictable applications. In that setting, the network and the application were usually optimized separately: the network observed packets, flows, queues, and paths, while application semantics remained mostly hidden. LLM workloads change this assumption. Their communication and state movement are generated by highly structured computations, such as collective communication in training, prefill/decode phases in serving, KV-cache growth during autoregressive decoding, attention sparsity, token importance, and expert routing. These semantics create an opportunity to move beyond workload-oblivious networking and build AI-centric networked systems: systems that expose LLM semantics to the networking, scheduling, memory-management, and kernel layers.
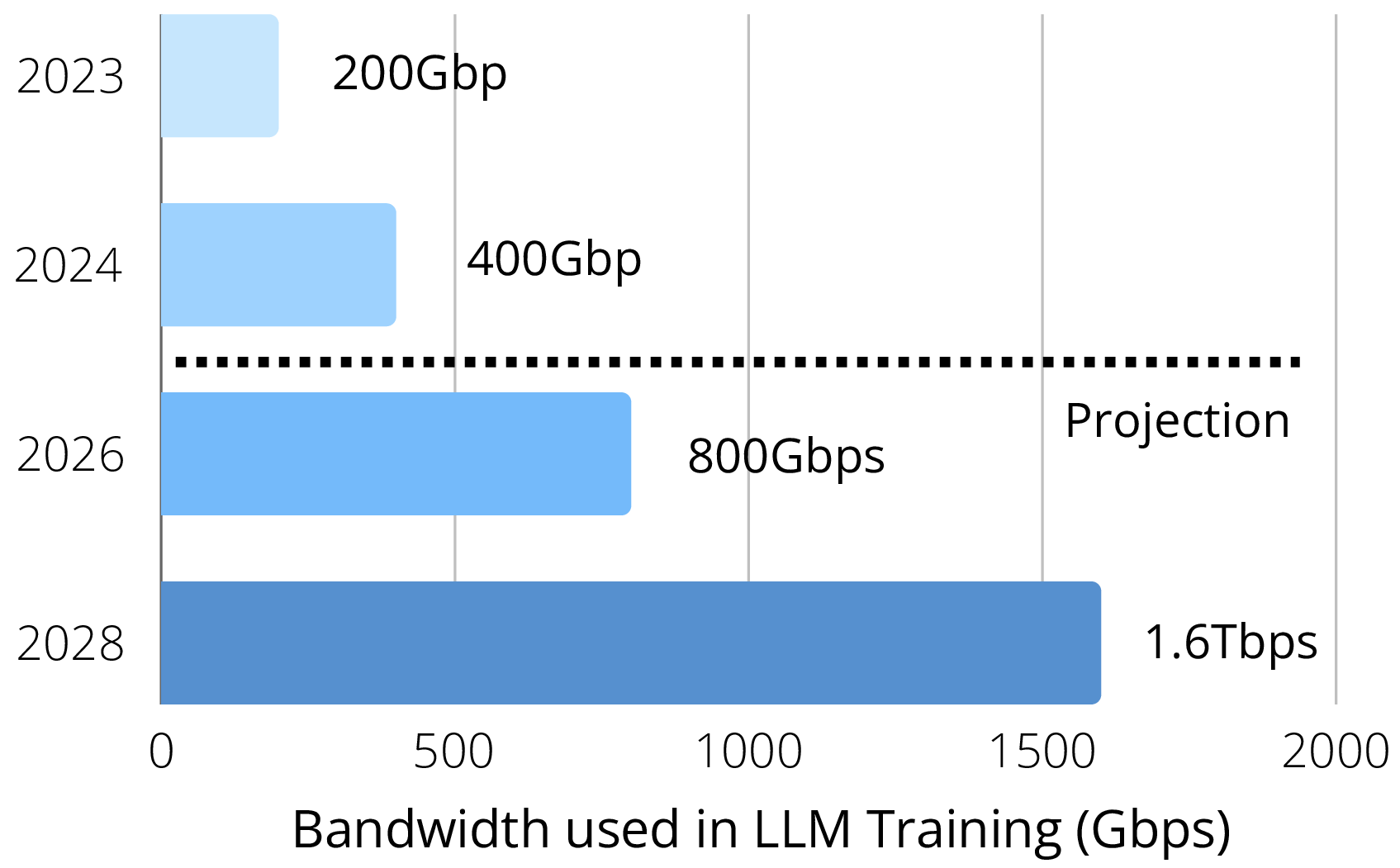 Figure 3: DCN Bandwidth Evolution.
Figure 3: DCN Bandwidth Evolution.
LLM training and serving rely on large clusters of accelerators connected by high-speed DCNs, such as Remote Direct Memory Access (RDMA)12 For more information on RDMA, refer to the Wikipedia page: [link].. My recent FCP13 Junxue Zhang, Han Tian, Xinyang Huang, Wenxue Li, Kaiqiang Xu, Dian Shen, and Kai Chen. FCP: Fast User-space RDMA Control Plane Setup for Elastic Computing. In Proc. of SoCC 2026, 2026 project optimizes the RDMA control plane for elastic computing, showing that AI clusters need efficient setup paths as well as fast data paths. Figure 3 illustrates the rapid bandwidth growth required by LLM applications. However, simply increasing bandwidth is not enough. The performance bottleneck is often determined by how the system moves model states, KV cache, gradients, activations, and tokens across GPUs and machines. These data objects are not generic bytes: they have different importance, lifetime, stability, and communication patterns. Therefore, the key challenge is to make the networked system understand what it is moving and why it is moving it.
LLM serving: KVFlow. In multi-instance LLM serving, one-shot request placement is insufficient because autoregressive decoding continuously grows the KV cache and changes runtime resource pressure. Existing live-migration systems move active requests by transferring the full KV cache before the destination can resume decoding. This design treats the KV cache as an opaque byte stream, so it delays memory reclamation, load balancing, and defragmentation. In KVFlow 14 Yu Zhao, Boyu Liu, Shihao Zhou, Zaige Fei, Junxue Zhang, Han Tian, Di Chai, Dian Shen, and Kai Chen. Efficient LLM Inference Rescheduling via Progressive KV Cache Migration, 2026. Manuscript, we observe that near-term decoding often depends on a temporally stable subset of critical KV-cache blocks. Based on this observation, KVFlow exposes lightweight block-level attention statistics from the attention kernel, identifies migration-friendly requests, and progressively migrates the KV cache: it first transfers the stable critical blocks for early handoff, then refills the remaining KV cache in the background. This co-design between attention semantics, runtime scheduling, KV-cache management, and network transfer reduces migration handoff latency by up to 6.89×, lowers migration-time KV-cache footprint by about 30%, and reduces P99 TTFT by 47.3% on average.
LLM training: Centrifuge. In LLM training, token filtering has shown strong promise for improving model utility by focusing learning on more informative tokens. However, existing systems fail to convert this algorithmic sparsity into end-to-end training speedups, because filtering only the loss does not preserve sparsity through the backward computation, and existing sparse GEMM libraries are inefficient for the moderate sparsity range of token filtering. In Centrifuge 15 Di Chai, Pengbo Li, Feiyuan Zhang, Yilun Jin, Han Tian, Kaiqiang Xu, Binhang Yuan, Dian Shen, Junxue Zhang, and Kai Chen. Unlocking Full Efficiency of Token Filtering in Large Language Model Training. In Proc. of ICLR 2026, 2026, we use algorithm-system co-design to unlock the full efficiency of token filtering. At the algorithm level, Centrifuge carefully modifies the memory-efficient attention backward kernel so that sparsity can propagate without corrupting gradients. At the system level, it transforms sparse GEMM into dimension-reduced dense GEMM by automatically updating the backward computation graph, thereby using highly optimized dense ML libraries. Centrifuge reduces backpropagation time by up to 49.9% and end-to-end training time by up to 34.7% when filtering 50% of tokens, while preserving the utility benefits of token filtering.
KVFlow and Centrifuge represent my broader research direction: building networked systems that are aware of LLM semantics and can optimize across layers that were previously separated. Looking forward, I will expand this agenda in three directions.
Semantic-aware networking. I will expose LLM semantics, such as KV-cache importance, token priority, request phase, expert routing, and latency objectives, to routing, scheduling, and load-balancing mechanisms. This enables the network to optimize useful data movement rather than bytes alone.
From DCN to general networked systems. I will extend my DCN methodology beyond inter-machine networks to host networking, GPU–CPU memory I/O, storage access, and memory-tier transfers. KV-cache offloading is one concrete example where network, memory, and runtime decisions must be co-optimized.
Broader AI workloads. Beyond LLM pretraining and serving, emerging workloads such as reinforcement-learning (RL) pipelines and on-policy distillation (OPD) introduce new communication and scheduling patterns. I will study how their workload-specific semantics can guide data movement, scheduling, and networked-system design.